迭代和递归的原理与实现——算法系列教程(c++版)
梦想不会自己发光,真正闪耀的是那个为梦狂奔的你。献给知行的孩子们!(Eric.He著)
1. 迭代(Iteration)是一种通过循环结构重复执行一段代码逻辑的编程方法。其本质是把复杂问题拆解为「重复执行的简单步骤」,通过 “逐步推进” 一步一步完成求解,是人类 “分步做事” 思维在编程中的直接体现。
2. 递归(Recursive)是一种通过函数自身调用自身的编程方法。其本质是将复杂的大问题分解为与原问题结构相似但规模更小的子问题,通过 “递推回归” 求解子问题最终聚合得到原问题的解。
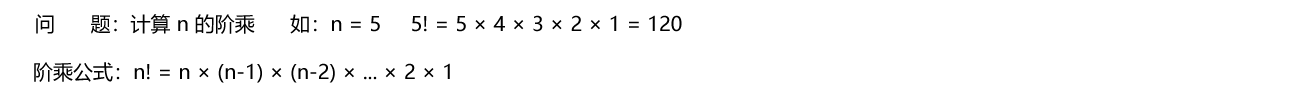
1. 迭代

2. 递归

教程目录导航
一、迭代原理
1.1 迭代定义
迭代是一种通过循环结构重复执行一段代码逻辑的编程范式,核心是:
- 有明确的循环变量(如 i、index),用于标记当前迭代的状态;
- 有清晰的终止条件(如 i < n、!isEmpty()),防止无限循环;
- 每一次循环称为一次 “迭代”,每次迭代都会更新循环变量,逐步逼近终止条件。
本质是把复杂问题拆解为「重复执行的简单步骤」,通过 “逐步推进” 完成求解。
1.2 关键特性
- 可控性强:循环变量和终止条件明确,能精准控制迭代的开始、结束和步长;
- 空间效率高:无需额外的调用栈(对比递归),仅使用少量临时变量,避免栈溢出;
- 通用性广:几乎所有编程场景都能用到(遍历、计算、逻辑处理),是实现枚举、排序、搜索等算法的基础;
- 可读性均衡:简单迭代(如遍历数组)可读性极高,复杂迭代(如嵌套循环)需注意代码结构。
二、递归原理
2.1 递归定义
其核心原理包含两个关键要素,缺一不可:
- 递推(分解):把原问题 F(n) 拆解为若干个结构相同、规模更小的子问题 F(n-1)、F(n-2)...,子问题的求解逻辑与原问题完全一致;
- 回归(终止):存在明确的终止条件(基线条件),当子问题规模缩小到一定程度时,无需再递归调用,可直接返回已知结果,避免函数无限递归。
简单来说,递归就是 “自己调用自己,直到触底反弹”,类似于 “查字典” 的逻辑:遇到不认识的字查字典,字典里可能还有不认识的字,继续查,直到查到认识的字,再反向推导理解原本的字。
2.2 关键特性
- 自相似性:原问题与子问题具有相同的逻辑结构,这是递归能够成立的前提;
- 分治性:将大问题拆解为小问题,降低问题求解的复杂度;
- 栈特性:递归调用依赖程序的 “调用栈”(系统自动维护),每一次递归调用都会将当前函数的上下文(参数、局部变量、返回地址)压入栈中,终止条件满足时再从栈中依次弹出上下文,逐步返回结果;
- 简洁性:递归代码通常比非递归(迭代)代码更简洁、可读性更强,无需手动维护复杂的中间状态。
2.3 核心前提
递归三个必要前提:
- 问题具有自相似性,即大问题可分解为结构一致的小问题;
- 存在明确的终止条件,避免无限递归(栈溢出);
- 子问题的规模能够逐步缩小,最终触达终止条件。
三、迭代与递归的核心区别
| 对比维度 | 递归 | 迭代 |
|---|---|---|
| 实现方式 | 函数自身调用 | 循环结构(for/while) |
| 内存占用 | 依赖系统调用栈,占用较高 | 手动维护变量,占用较低 |
| 可读性 | 强,代码简洁 | 弱,复杂问题逻辑繁琐 |
| 性能 | 存在栈操作开销,略低 | 无额外开销,性能更高 |
| 栈溢出风险 | 递归深度过大时存在风险 | 无栈溢出风险 |
| 适用场景 | 自相似、分治类问题 | 常规循环求解、深度较大的问题 |
四、递归实现步骤
要实现一个正确的递归,通常遵循以下 3 个步骤:
步骤 1:设计递推关系
将原问题分解为子问题,通过调用自身求解子问题,并将子问题的结果整合,得到原问题的解。递推关系需保证问题规模逐步缩小,最终触达终止条件。例如:
- 求解 “1 到 100 之间的质数”的递推关系:对当前num进行质数验证,若为质数则输出,随后递归遍历num+1。
- 百钱买百鸡的递推关系:
- 固定x,逐步递增y进行试探,直到y超出范围;
- y遍历完毕后,递增x,重新从y=0开始试探,形成递归分支;
步骤 2:定义递归函数与参数
明确函数的功能(求解什么问题),设计合理的参数,参数需能体现问题规模的变化(如 n 表示问题规模,递归时传递 n-1 缩小规模)。例如:
- 求解 “1 到 100 之间的质数”的函数:void f(int num)
- 百钱买百鸡的函数:void f(int x, int y)
步骤 3:设定终止条件(基线条件)
明确递归的 “边界”,当问题规模缩小到某一程度时,直接返回已知结果,不再调用自身。这是递归的 “出口”,缺少终止条件会导致栈溢出错误。例如:
- 求质数的终止条件:
- i × i > n( 即i > sqrt(n) ),说明n无法被 2 到sqrt(n)的整数整除,是质数;
- n % i == 0,说明n能被i整除,不是质数;
- 百钱买百鸡的终止条件:
- 找到合法解:x+y+z=100 且 5x+3y+z/3=100,同时 z>=0、z是 3 的倍数;
- 遍历完所有可能:x超过最大取值(14)或 y超过最大取值(25),停止当前分支递归;
五、递归分类
根据递归调用的方式和场景,可分为两种常见类型:
3.1 直接递归
函数直接调用自身,这是最常见的递归形式。例如:计算阶乘的函数 factorial(n) 直接调用 factorial(n-1)。
3.2 直接递归
两个或多个函数相互调用,形成递归环,也称为 “互递归”。例如:函数 A() 调用 B(),函数 B() 又调用 A(),需注意避免无限循环。
六、优化思路
递归的缺点是可能产生大量重复调用(导致时间复杂度飙升)和栈溢出(递归深度过大),常见优化方向有:
- 记忆化递归(缓存优化):通过缓存(如字典、数组)存储已经求解过的子问题结果,避免重复计算,将时间复杂度从指数级降低到线性级。适用于存在大量重复子问题的场景(如斐波那契数列、爬楼梯问题)。
- 尾递归优化:如果递归调用是函数的最后一个操作(即递归调用的结果直接返回,无需后续计算),称为尾递归。部分编程语言(如 Scala、Erlang)会对尾递归进行优化,将栈空间复用,避免栈溢出;Python、Java 默认不支持尾递归优化,需手动转换为迭代。
- 递归转迭代:对于递归深度较大的场景,可手动模拟调用栈的过程,将递归转换为迭代(循环),避免栈溢出问题,这是最通用的优化手段。
七、适用场景
递归适用于具有自相似性、可分治的问题,常见包括:
- 数学问题求解(如阶乘计算、斐波那契数列、组合排列数计算);
- 树形结构操作(如二叉树的遍历、查找、构建,N 叉树的递归遍历);
- 分治类问题(如归并排序、快速排序、汉诺塔问题);
- 回溯类问题(如子集生成、全排列、迷宫求解、八皇后问题);
- 动态规划的递归实现(带记忆化的递归,即 “自顶向下” 的动态规划)。
八、代码示例
下面以 “计算 n 的阶乘” 为例,展示递归的实现(阶乘定义:n! = n × (n-1) × (n-2) × ... × 2 × 1 )

算法解析
- 递推关系:n! = n × (n-1)!
- 定义递归函数与参数:long long factorial(int n)
- 设定终止条件:当 n == 0 时,直接返回 1,这是递归的 “出口”
#include <iostream>
using namespace std;
// 阶乘递归函数
// 函数功能:计算非负整数n的阶乘
// 参数n:待计算阶乘的非负整数
// 返回值:n的阶乘结果(long long类型避免整数溢出)
long long factorial(int n) {
// 1. 递归终止条件(基线条件)
if (n == 0) {
return 1;
}
// 2. 递归调用(递推关系)
// 利用公式 n! = n × (n-1)!,调用自身计算(n-1)的阶乘
return n * factorial(n - 1);
}
int main() {
int num;
cout << "请输入一个非负整数:";
cin >> num;
// 合法性校验:负数没有阶乘
if (num < 0) {
cout << "错误:负数不存在阶乘!" << endl;
return 1;
}
// 调用递归函数计算阶乘
long long result = factorial(num);
cout << num << "! = " << result << endl;
return 0;
}
执行流程解析
以 factorial(5) 为例,递归调用与返回过程如下(“递” 的过程压栈,“归” 的过程出栈):
1.factorial(5) → 调用 factorial(4),压栈;
2.factorial(4) → 调用 factorial(3),压栈;
3.factorial(3) → 调用 factorial(2),压栈;
4.factorial(2) → 调用 factorial(1),压栈;
5.factorial(1) 触达终止条件,返回 1;
6.factorial(2) 计算 2×1=2,返回 2;
7.factorial(3) 计算 3×2=6,返回 6;
8.factorial(4) 计算 4×6=24,返回 24;
9.factorial(5) 计算 5×24=120,返回最终结果。
九、优缺点
优点
- 代码简洁优雅,可读性强,开发效率高,无需手动维护复杂的循环逻辑;
- 天然适配具有自相似性的问题(如树形结构、分治问题),逻辑更贴合问题本质;
- 无需提前规划问题的求解路径,通过递推自动分解问题。
缺点
- 效率损耗:递归调用涉及函数入栈 / 出栈操作,存在一定的性能开销,比迭代略慢;
- 栈溢出风险:递归深度过大时(如求解 fibonacci(1000)),系统调用栈会超出最大限制,抛出 StackOverflowError;
- 重复计算:未优化的递归会对相同子问题进行多次计算,导致时间复杂度呈指数级增长(如原生斐波那契递归的时间复杂度为 O (2ⁿ))。
十、总结
- 递归的核心是大问题分解为相似小问题 + 明确终止条件 + 自身调用,依赖系统调用栈实现;
- 实现关键是 “定义递推关系、设定终止条件”,优化核心是避免重复计算和栈溢出;
- 分为直接递归和间接递归,记忆化递归、尾递归是常见优化手段;
- 适用于树形结构、分治、回溯等具有自相似性的场景,优势是简洁可读,劣势是存在性能损耗和栈溢出风险;
- 实际开发中,需根据问题规模和场景选择递归或迭代,大规模问题优先使用迭代或优化后的递归。
返回顶部