大规模数据排序问题——算法系列教程(c++版)
梦想不会自己发光,真正闪耀的是那个为梦狂奔的你。献给知行的孩子们!(Eric.He著)
归并排序、快速排序是「分治算法」最经典、最核心的两个落地实现,二者的排序逻辑完全基于分治思想,是算法学习中必须吃透的核心知识点。
本教程以及两者的特性对比、优缺点和适用场景,内容从基础到进阶,让大家彻底理解「分治思想」的核心逻辑,并掌握归并排序、快速排序的原理、完整代码实现。
- 归并排序:「合」的过程是核心难点,「分」的过程很简单;
- 快速排序:「分」的过程是核心难点,「合」的过程几乎不需要做任何操作;
教程目录导航
一、归并排序 (Merge Sort)
问题描述:
- 将数组从小到大(或从大到小)排序,严格遵循「分 → 治 → 合」三步
算法解析:
- 分 (Divide) - 拆分问题
将当前待排序的数组,从中间位置拆分成左右两个子数组:
- 左子数组:arr[left ... mid]
- 右子数组:arr[mid+1 ... right]
递归对左右两个子数组执行「分」操作,直到拆分后的子数组只有 1 个元素(递归终止条件)。
为什么终止条件是 1 个元素?因为一个元素的数组,本身就是有序的,这就是「治」的直接解。
- 治 (Conquer) - 求解子问题
递归处理拆分后的左右子数组,直到所有子数组都被拆分为单个元素(天然有序),这一步是递归的自然过程,无需额外操作。
- 合 (Combine) - 合并子问题的解【核心】
这是归并排序的灵魂步骤,也是唯一的难点。
将两个已经有序的子数组(左子数组、右子数组),合并成一个新的有序数组,并把这个有序数组覆盖回原数组的对应位置。
这个合并两个有序数组的操作,也被称为「二路归并」,是归并排序的核心操作。
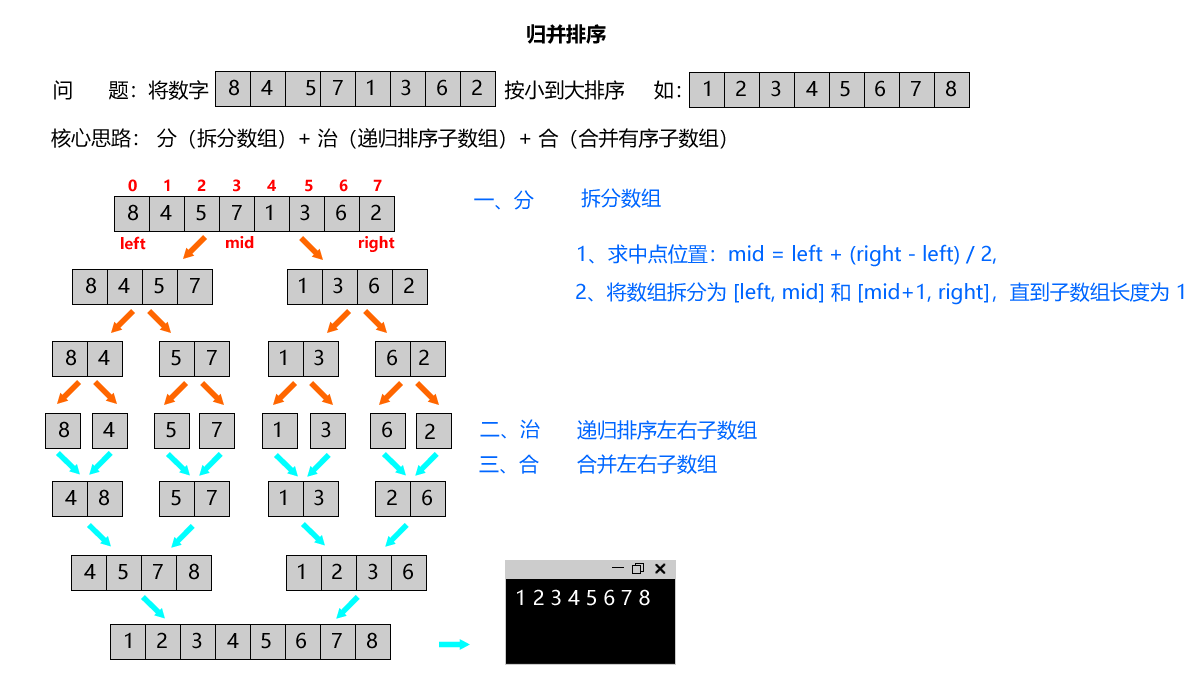
- 以数组 [8,4,5,7,1,3,6,2] 为例,直观理解归并排序的全过程:
- 分:[8,4,5,7,1,3,6,2] → [8,4,5,7] + [1,3,6,2]
- 分:[8,4,5,7] → [8,4] + [5,7];[1,3,6,2] → [1,3] + [6,2]
- 分:[8,4]→[8]+[4];[5,7]→[5]+[7];[1,3]→[1]+[3];[6,2]→[6]+[2](终止,所有子数组都是有序的单个元素)
- 合:[8]+[4]→[4,8];[5]+[7]→[5,7];[1]+[3]→[1,3];[6]+[2]→[2,6]
- 合:[4,8]+[5,7]→[4,5,7,8];[1,3]+[2,6]→[1,2,3,6]
- 合:[4,5,7,8]+[1,2,3,6]→[1,2,3,4,5,6,7,8](最终有序数组)
#include <iostream>
#include <vector>
using namespace std;
// 合并操作:将两个有序子数组[left, mid]和[mid+1, right]合并为一个有序数组
// arr:原数组
// temp:临时数组(用于存储合并结果,避免频繁创建数组)
// left:左子数组起始索引
// mid:拆分点(左子数组结束索引)
// right:右子数组结束索引
void merge(vector<int>& arr, vector<int>& temp, int left, int mid, int right) {
// 1. 初始化指针
int i = left; // 左子数组指针
int j = mid + 1; // 右子数组指针
int k = left; // 临时数组指针
// 2. 合并两个有序子数组到临时数组
while (i <= mid && j <= right) {
if (arr[i] <= arr[j]) {
temp[k++] = arr[i++];
} else {
temp[k++] = arr[j++];
}
}
// 3. 处理左子数组剩余元素
while (i <= mid) {
temp[k++] = arr[i++];
}
// 4. 处理右子数组剩余元素
while (j <= right) {
temp[k++] = arr[j++];
}
// 5. 将临时数组的有序结果复制回原数组
for (int idx = left; idx <= right; idx++) {
arr[idx] = temp[idx];
}
}
// 分治实现归并排序(递归版)
// arr:待排序数组
// temp:临时数组(复用,减少内存开销)
// left:当前排序区间起始索引
// right:当前排序区间结束索引
void mergeSort(vector<int>& arr, vector<int>& temp, int left, int right) {
// 递归终止条件:区间只有1个元素或空(天然有序)
if (left >= right) {
return;
}
// 1. 分:计算中间点,拆分为左、右子数组
int mid = left + (right - left) / 2; // 避免(left+right)溢出
// 2. 治:递归排序左、右子数组
mergeSort(arr, temp, left, mid); // 排序左区间[left, mid]
mergeSort(arr, temp, mid + 1, right); // 排序右区间[mid+1, right]
// 3. 合:合并两个有序子数组
merge(arr, temp, left, mid, right);
}
// 包装函数:简化调用(无需手动传入temp、left、right)
void mergeSort(vector<int>& arr) {
if (arr.empty() || arr.size() == 1) {
return; // 空数组或单元素数组无需排序
}
vector<int> temp(arr.size()); // 创建临时数组(仅创建一次,复用)
mergeSort(arr, temp, 0, arr.size() - 1);
}
// 辅助函数:打印数组
void printArray(const vector<int>& arr) {
for (int num : arr) {
cout << num << " ";
}
cout << endl;
}
int main() {
// 测试数组
vector<int> arr = {8, 4, 5, 7, 1, 3, 6, 2};
cout << "排序前数组:";
printArray(arr);
// 归并排序
mergeSort(arr);
cout << "排序后数组:";
printArray(arr);
return 0;
}
输出结果
排序前数组:8 4 5 7 1 3 6 2
排序后数组:1 2 3 4 5 6 7 8
二、快速排序 (Quick Sort)
快速排序也是严格遵循分治三步思想的排序算法,由大佬霍尔提出,也叫「霍尔排序」,核心特征:先分后合,分为核心,合无操作
问题描述:
- 将数组从小到大排序,严格遵循「分 → 治 → 合」三步,合的过程无需任何操作,是快排的核心亮点
算法解析:
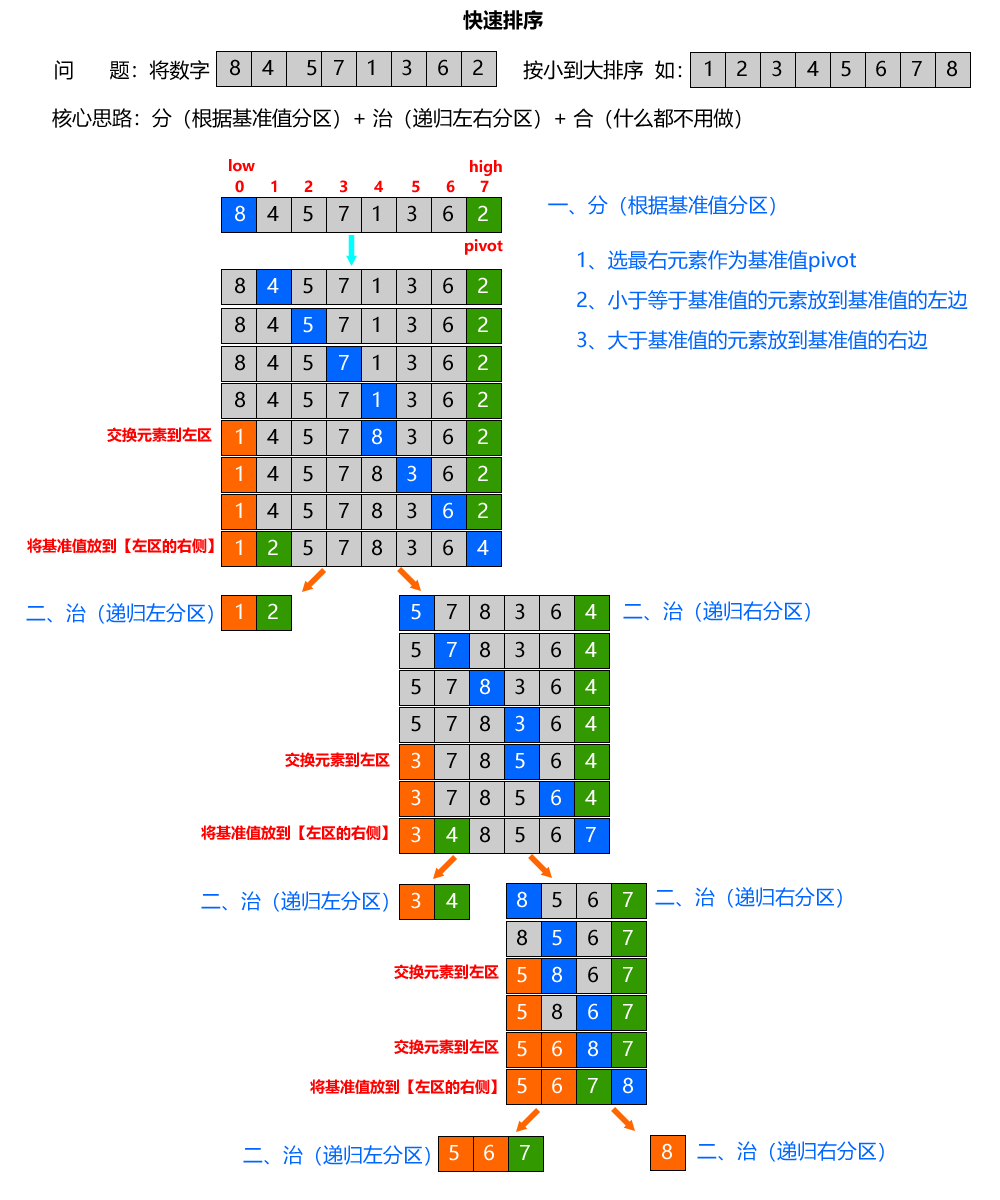
- 分 (Divide) - 分区操作【核心中的核心】
- 选基准值 (Pivot):从当前待排序数组中,任选一个元素作为基准值(比如选最左、最右、中间、随机元素);
- 分区操作 (Partition):遍历当前数组,将数组中所有小于等于基准值的元素放到基准值的左边,将所有大于基准值的元素放到基准值的右边;
- 分区完成后,基准值会被放到一个固定的最终位置(这个位置在排序完成后不会再改变),此时数组被基准值拆分为:
- 左子数组:arr[low ... pivot_idx-1] (所有元素 ≤ 基准值)
- 右子数组:arr[pivot_idx+1 ... high](所有元素 > 基准值)
- 治 (Conquer) - 求解子问题
递归地对基准值左边的子数组、右边的子数组,重复执行「选基准值 + 分区」的操作;
递归终止条件:子数组的范围 low >= high(即子数组只有 1 个元素或空,本身有序)。
- 合 (Combine) - 合并子问题的解
这一步:什么都不用做!
因为分区后,左子数组的所有元素都 ≤ 基准值,右子数组的所有元素都 > 基准值;递归完成后,左、基准、右三部分自然就是有序的,无需任何合并操作。
这是快排对比归并的最大优势:空间开销极小,支持原地排序。
快速排序的核心概念:基准值 (Pivot)
基准值的选择,直接决定了快速排序的效率,这是快排的关键细节,必须掌握:
- 基准值的作用:作为分区的「分界线」,分区后基准值的位置永久固定;
- 常见选择方式:
- 选最左元素:pivot = arr[low]
- 选最右元素:pivot = arr[high] (本文代码采用此方式,最易实现)
- 选中间元素:pivot = arr[(low+high)//2]
- 随机选元素:pivot = arr[random.randint(low, high)] (最优选择,避免极端情况)
#include <iostream>
#include <vector>
using namespace std;
// 核心分区函数:返回基准值的【最终索引】,实现原地分区
// 处理区间 arr[low ... high],选择【最右侧元素】作为基准值(最易实现,笔试首选)
int partition(vector& arr, int low, int high) {
int pivot = arr[high]; // 基准值
int i = low - 1; // i:小于等于基准值区域的【右边界】
// 遍历 [low, high-1] 所有元素,完成分区
for (int j = low; j < high; j++) {
// 当前元素 ≤ 基准值 → 划入左区
if (arr[j] <= pivot) {
i++; // 左区边界右移
swap(arr[i], arr[j]); // 交换元素到左区
}
}
// 将基准值放到【左区的右侧】,即基准值的最终位置
swap(arr[i + 1], arr[high]);
return i + 1; // 返回基准值的索引,用于后续递归
}
// 快速排序递归核心函数:处理 arr[low ... high] 区间的排序
void quickSort(vector& arr, int low, int high) {
// 递归终止条件:区间只有1个元素或空,无需排序
if (low >= high) {
return;
}
// ========== 第一步:分(Divide) 核心-分区 ==========
int pivotIdx = partition(arr, low, high);
// ========== 第二步:治(Conquer) ==========
quickSort(arr, low, pivotIdx - 1); // 递归排序左区间
quickSort(arr, pivotIdx + 1, high); // 递归排序右区间
// ========== 第三步:合(Combine) ==========
// 无需任何操作!分区后左区≤基准≤右区,递归完成后自然有序
}
// 快速排序对外封装函数,简化调用
void quickSort(vector& arr) {
if (arr.empty() || arr.size() == 1) {
return;
}
quickSort(arr, 0, arr.size() - 1);
}
int main() {
// 测试快速排序
vector arr = {8,4,5,7,1,3,6,2};
cout << "快速排序前:";
printArr(arr);
quickSort(arr);
cout << "快速排序后:";
printArr(arr2);
return 0;
}
输出结果
快速排序前:8 4 5 7 1 3 6 2
快速排序后:1 2 3 4 5 6 7 8
三、算法对比
这是本文的重中之重,也是面试 / 笔试的高频考点,两者都是分治思想的实现,O(n log n) 级别的排序算法,但特性差异巨大,整理成表格,一目了然
| 对比维度 | 归并排序 (Merge Sort) | 快速排序 (Quick Sort) |
|---|---|---|
| 分治核心 | 合为核心,分很简单 | 分为核心,合无操作 |
| 时间复杂度 | 最优 / 最坏 / 平均:O(n log n)(绝对稳定) | 平均:O(n log n),最坏:O(n^2),可优化 |
| 空间复杂度 | O(n)(必须开辟临时空间,无法原地) | O( log n)(原地排序,递归栈开销) |
| 排序稳定性 | 稳定排序 | 不稳定排序 |
| 元素移动方式 | 元素「复制」到临时数组 | 元素「交换」位置,原地排序 |
| 适用场景 | 外部排序(磁盘大文件)、要求稳定排序的场景 | 内部排序(内存数据)、追求极致效率的场景 |
| 实际应用 | 少量场景(需要稳定 + 大文件) | 工业级标准排序算法(Python/Java 底层) |
四、总结
- 分治思想是根:归并、快排都是分治的落地,分治 = 分 + 治 + 合,归并「合难分易」,快排「分难合易」;
- 归并排序:稳定、效率绝对稳定O(n log n),缺点是空间开销大O(n),适合外部排序、稳定需求;
- 快速排序:不稳定、平均效率O(n log n),优点是空间开销极小O( log n),是工业级首选排序算法;
- 两者都是递归算法,都是 O(n log n) 级别的高效排序算法,是排序算法的天花板;
- 所有 O(n^2) 级别的排序(冒泡、选择、插入)在数据量较大时,效率远低于这两个算法。
至此,分治思想、归并排序、快速排序的原理 + 实现 + 特性已经全部讲完,希望能帮你彻底吃透这个核心知识点!
返回顶部