树结构经典应用场景——数据结构系列教程(c++版)
梦想不会自己发光,真正闪耀的是那个为梦狂奔的你。献给知行的孩子们!(Eric.He著)
树是一种非线性层次化数据结构,其核心特点是一个根节点、多个子节点、无环连通,这种结构天然适配具有层级关系的场景。在当今这个信息大爆炸的时代,海量数量无处不在,树结构在海量数据高效查找、排序的场景应用也非常广泛。本文将详细讲解树在数据存储、数据索引 、哈夫曼编码与解码、Top K中的应用,内容由浅入深,所有代码可直接编译运行。
树结的实现方式:
学习经典应用场景前,请根据上面的教程封装好自定义树,所有场景实例直接复用
教程目录导航
一、各类树结构的应用场景
| 树结构类型 | 核心特点 | 典型应用场景 |
|---|---|---|
| 二叉搜索树(BST) | 左小右大,支持动态查找 | 简单的有序数据存储 |
| 平衡二叉树(AVL / 红黑树) | 自平衡,避免退化为链表 | 内存数据库索引、有序集合 |
| B 树 / B + 树 | 多叉平衡,磁盘友好 | 关系型数据库索引 |
| 堆(完全二叉树) | 最大 / 最小值快速访问 | 优先队列、堆排序、Top K 问题 |
| Trie 树 | 前缀共享,字符串高效匹配 | 自动补全、路由匹配 |
| 决策树 | 特征划分,分类回归 | 机器学习分类任务 |
| 多叉树 | 根目录作为树的根节点,子目录是中间节点,文件是叶子节点; | Windows 的资源管理器 |
| 抽象语法树 | 将表达式拆解为树结构,运算符作为中间节点,操作数作为叶子节点。 | 编译器与表达式计算 |
| 博弈树 | 用于模拟棋类、游戏等博弈过程,节点代表游戏状态,边代表玩家的一步操作 | AlphaGo 对围棋局面的评估与落子决策。 |
| 控件树 | 根节点为窗口本身,子节点为各种容器,叶子节点为按钮、文本框等基础控件; | Android 的 ViewTree、网页的 DOM 树 |
一、有序数据存储
将有序数组转换为二叉搜索树。利用有序数组的特性和二叉搜索树 “左子树值都小、右子树值都大” 的规则,构建平衡树。
问题描述:
- 给你一个整数数组 nums ,其中元素已经按升序排列,请你将其转换为一棵 平衡 二叉搜索树。
- 如:nums = [-10,-3,0,5,9]
- 结果(层序):[0,-10,5,null,-3,null,9] 或 [0,-3,9,-10,null,5]
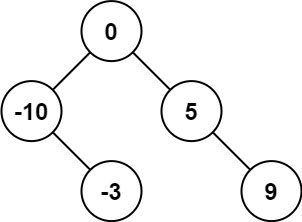
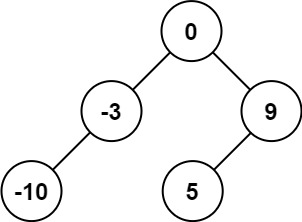
算法解析:
我们可以选择中间数字作为二叉搜索树的根节点,这样分给左右子树的数字个数相同或只相差 1,可以使得树保持平衡。如果数组长度是奇数,则根节点的选择是唯一的,如果数组长度是偶数,则可以选择中间位置左边的数字作为根节点或者选择中间位置右边的数字作为根节点,选择不同的数字作为根节点则创建的平衡二叉搜索树也是不同的。
- 方法一:选择中间位置左边的数字作为根节点
- 根节点的下标为:mid=(left+right)/2
- 时间复杂度:O(n),其中 n 是数组的长度。每个数字只访问一次。
- 空间复杂度:O(logn),其中 n 是数组的长度。空间复杂度不考虑返回值,因此空间复杂度主要取决于递归栈的深度,递归栈的深度是 O(logn)。
- 方法二:选择中间位置右边的数字作为根节点
- 根节点的下标为:mid=(left+right+1)/2
- 时间复杂度:O(n),其中 n 是数组的长度。每个数字只访问一次。
- 空间复杂度:O(logn),其中 n 是数组的长度。空间复杂度不考虑返回值,因此空间复杂度主要取决于递归栈的深度,递归栈的深度是 O(logn)。
#include <iostream>
#include"LinkedBSTree.h"
using namespace std;
// 选择中间位置左边的数字作为根节点
void leftArrayToBST(int nums[], LinkedBSTree<int> &tree, int left, int right) {
if (left > right) {
return;
}
// 总是选择中间位置左边的数字作为根节点
int mid = (left + right) / 2;
tree.insertNode(nums[mid]);
leftArrayToBST(nums, tree, left, mid - 1);
leftArrayToBST(nums, tree, mid + 1, right);
}
// 选择中间位置右边的数字作为根节点
void rightArrayToBST(int nums[], LinkedBSTree<int> &tree, int left, int right) {
if (left > right) {
return;
}
// 总是选择中间位置左边的数字作为根节点
int mid = (left + right + 1) / 2;
tree.insertNode(nums[mid]);
rightArrayToBST(nums, tree, left, mid - 1);
rightArrayToBST(nums, tree, mid + 1, right);
}
// 测试案例
int main() {
int nums[] = {-10,-3,0,5,9};
int length = size(nums);
LinkedBSTree<int> leftTree;
printf("\n测试方法一:左边的数字作为根节点\n");
leftArrayToBST(nums, leftTree, 0, length - 1);
leftTree.levelOrder();
LinkedBSTree<int> rightTree;
printf("\n测试方法二:左边的数字作为根节点\n");
rightArrayToBST(nums, rightTree, 0, length - 1);
rightTree.levelOrder();
return 0;
}
输出结果
测试方法一:左边的数字作为根节点
0 -10 5 -3 9
测试方法二:左边的数字作为根节点
0 -3 9 -10 5
三、数据索引
在实际软件项目中,数据会随着时间的增长而不断增加,要实现海量数据的高性能增删查改,数据索引是提升数据操作效率的关键。我们可以利用搜索二叉树、AVL自平衡树和红黑树实现数据索引。红黑树作为平衡的二叉搜索树,兼顾了插入 / 删除的旋转开销和查询效率,是数据索引的经典实现方案(如 Redis 的 Sorted Set 底层就用到红黑树)。
本教程将从 “原理→实现→应用” 全流程讲解如何用红黑树实现数据索引,最终完成一个支持插入、查询的轻量级数据索引模块。
实例中只要将红黑树代码部分替换为搜索二叉树和AVL自平衡树代码,就可以实现搜索二叉树、AVL自平衡树数据索引,大家可以比较一下它们的操作效率差。
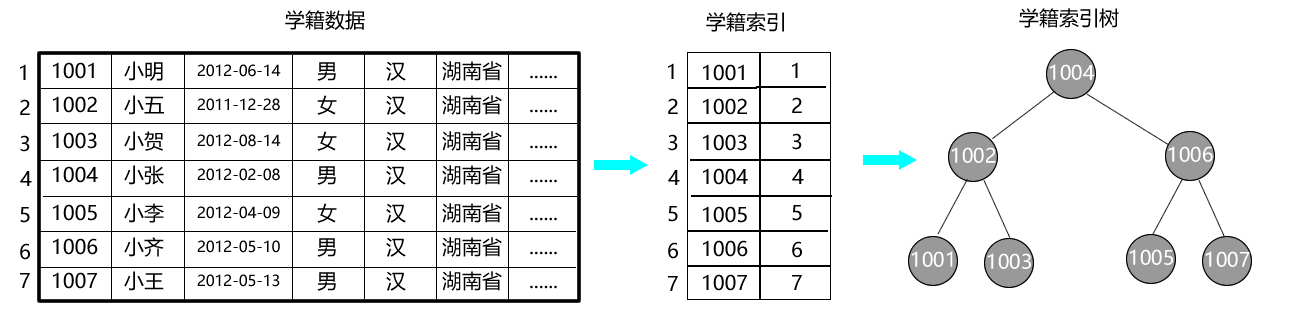
问题描述:
- 我们将实现一个简单的学籍管理模块,100万条学籍数据存储在student_db.txt文件中,以学号为键,文件行号为值的学籍索引存储在student_index.txt文件中,核心功能包括:
- 生成学籍文件
- 生成索引文件
- 加载索引文件
- 查找学生
- 插入学生
- 文件中存储的数据:
- 学籍数据(student_db.txt):学号、姓名、出生日期、性别、民族、地址、入学总分、学校、班级、状态
- 学籍索引(student_index.txt):学号、行号
算法解析:
- 生成学籍文件
- 输入学籍数据条数
- 循环生成学籍数据
- 利用fstream以每行一条学籍记录写入学籍数据文件中
- 生成索引文件
- 根据学籍信息生成学籍索引文件
- 利用fstream读取学籍数据
- 将每条学籍的学号和行号写入学籍索引文件中
- 加载索引文件
- 利用fstream读取学籍索引
- 根据学籍索引,生成红黑树数据索引
- 查找学生
- 根据学号查找学生详细信息
- 输入待查找的学号
- 从红黑树数据索引中查找学号对应的行号
- 从学籍文件中定位到行号,读取该行数据
- 插入学生
- 输入学号、姓名、出生日期、性别、民族、地址、入学总分、学校、班级信息
- 将学籍信息写入学籍数据文件末尾
- 将学号和行号写入学籍引用文件末尾
- 将学号和行号插入红黑树数据索引中
#include <iostream>
#include "Entitys.h"
#include "LinkedBSTree.h"
#include "LinkedAVLTree.h"
#include "LinkedRBTree.h"
using namespace std;
int lineNumber = 0;//行号计数
//去除首尾空格(trim)
std::string trim(const std::string& str) {
auto start = str.find_first_not_of(" \t\n\r\f\v");
if (start == std::string::npos) return "";
auto end = str.find_last_not_of(" \t\n\r\f\v");
return str.substr(start, end - start + 1);
}
// 将有序索引数据转换为二叉搜索树(选择中间位置左边的数据作为根节点,处理有序索引数据退化问题)
void dataToTree(fstream &iin, auto indexTree, int left, int right) {
if (left > right) {
return;
}
int row = 0;
string line;
StudentIndex node;
// 总是选择中间位置左边的数字作为根节点
int mid = (left + right) / 2;
row = 22*(mid-1);//计算行偏移量
iin.seekp(row, std::ios::beg);//将指针移动到文件开头后第N个字节处
getline(iin,line);
node.id = stoi(trim(line.substr(0,10)));
node.row = stoi(trim(line.substr(11,10)));
indexTree->insertNode(node);
dataToTree(iin, indexTree, left, mid - 1);
dataToTree(iin, indexTree, mid + 1, right);
}
//生成索引文件
void buildIndex()
{
int i = 1;
//清空索引文件
ofstream iout("student_index.txt", std::ios::trunc);
//读取学籍数据
ifstream sin("student_db.txt");
string line;
while(getline(sin,line))
{
string id = line.substr(0,10);
string row = to_string(i++);//行号
//将每条学籍的学号和行号写入学籍索引文件中
//学籍索引每行20个字节,换行符占2个字节,合计22个字节
id.length() < 10 ? id = string(10 - id.length(), ' ') + id : id = id.substr(0,10);
row.length() < 10 ? row = string(10 - row.length(), ' ') + row : row = row.substr(0,10);
iout<<id<<row<<endl;
}
iout.close();
sin.close();
}
//加载索引文件(普通版,加载搜索二叉树数据索引时,如果数据有序退化为线性结构)
void loadIndex(auto indexTree){
string line;
StudentIndex node;
//读取学籍索引
ifstream iin("student_index.txt");
while(getline(iin,line))
{
node.id = stoi(trim(line.substr(0,10)));
node.row = stoi(trim(line.substr(11,10)));
//根据学籍索引,生成红黑树
indexTree->insertNode(node);
}
iin.close();
}
//加载索引文件(优化版,解决加载搜索二叉树数据索引时,有序数据退化为线性结构问题)
void loadIndexNew(auto indexTree){
fstream iin("student_index.txt");////读取学籍索引
dataToTree(iin,indexTree,1,lineNumber);
iin.close();
}
//查找学生
void findById(auto indexTree, int id)
{
//从AVL树或红黑树中查找学号对应的行号
StudentIndex node = indexTree.searchNode({id,0});
//从学籍数据中定位到行号,读取该行数据
string line;
fstream sin("student_db.txt");
int n = 132*(node.row-1);//计算行偏移量
sin.seekp(n, std::ios::beg);//将指针移动到文件开头后第N个字节处
getline(sin,line);
sin.close();
std::cout<<line<<std::endl;
}
//插入学生
void inserStudent(auto indexTree, Student stu)
{
//将每条学籍信息的长度处理为相同长度(不足后面补空格,超出截取)
string id = to_string(stu.id);
string score = to_string(stu.score);
//学籍记录每行占130个字节,换行符占2个字节,合计132个字节
id.length() < 10 ? id = string(10 - id.length(), ' ') + id : id = id.substr(0,10);
stu.name.length() < 10 ? stu.name = string(10 - stu.name.length(), ' ') + stu.name : stu.name = stu.name.substr(0,10);
stu.dob.length() < 12 ? stu.dob = string(12 - stu.dob.length(), ' ') + stu.dob : stu.dob = stu.dob.substr(0,12);
stu.sex.length() < 8 ? stu.sex = string(8 - stu.sex.length(), ' ') + stu.sex : stu.sex = stu.sex.substr(0,8);
stu.gender.length() < 10 ? stu.gender = string(10 - stu.gender.length(), ' ') + stu.gender : stu.gender = stu.gender.substr(0,10);
stu.address.length() < 30 ? stu.address = string(30 - stu.address.length(), ' ') + stu.address : stu.address = stu.address.substr(0,30);
score.length() < 10 ? score = string(10 - score.length(), ' ') + score : score = score.substr(0,10);
stu.school.length() < 20 ? stu.school = string(20 - stu.school.length(), ' ') + stu.school : stu.school = stu.school.substr(0,20);
stu.team.length() < 10 ? stu.team = string(10 - stu.team.length(), ' ') + stu.team : stu.team = stu.team.substr(0,10);
stu.status.length() < 10 ? stu.status = string(10 - stu.status.length(), ' ') + stu.status : stu.status = stu.status.substr(0,10);
//将学籍信息写入学籍数据文件末尾
ofstream sout("student_db.txt", ios::app);
sout<<id<<stu.name<<stu.dob<<stu.sex<<stu.gender<<stu.address<<score<<stu.school<<stu.team<<stu.status<<endl;
sout.close();
//将学号和行号写入学籍索引文件末尾
ofstream iout("student_index.txt", ios::app);
lineNumber++;
string rows = to_string(lineNumber);
rows.length() < 10 ? rows = string(10 - rows.length(), ' ') + rows : rows = rows.substr(0,10);
iout<<id<<rows<<endl;
iout.close();
//将学号和行号插入红黑树数据索引中
StudentIndex node;
node.id = stu.id;
node.row = lineNumber;
indexTree->insertNode(node);
}
//生成学籍数据
void buildDate(int x)
{
ofstream sout("student_db.txt", ios::app);
for(int i=1;i<=x;i++)
{
Student stu;
stu.id = 1000+i;
stu.name = "aaaa"+to_string(i);
stu.dob = "2012-05-18";
stu.sex = "男";
stu.gender = "汉";
stu.address = "湖南省湘潭县石潭镇";
stu.score = 400;
stu.school = "石潭傎芙蓉中学";
stu.team = "36";
stu.status = "在读";
//将每条学籍信息的长度处理为相同长度(不足后面补空格,超出截取)
string id = to_string(stu.id);
string score = to_string(stu.score);
//学籍记录每行占130个字节,换行符占2个字节,合计132个字节
id.length() < 10 ? id = string(10 - id.length(), ' ') + id : id = id.substr(0,10);
stu.name.length() < 10 ? stu.name = string(10 - stu.name.length(), ' ') + stu.name : stu.name = stu.name.substr(0,10);
stu.dob.length() < 12 ? stu.dob = string(12 - stu.dob.length(), ' ') + stu.dob : stu.dob = stu.dob.substr(0,12);
stu.sex.length() < 8 ? stu.sex = string(8 - stu.sex.length(), ' ') + stu.sex : stu.sex = stu.sex.substr(0,8);
stu.gender.length() < 10 ? stu.gender = string(10 - stu.gender.length(), ' ') + stu.gender : stu.gender = stu.gender.substr(0,10);
stu.address.length() < 30 ? stu.address = string(30 - stu.address.length(), ' ') + stu.address : stu.address = stu.address.substr(0,30);
score.length() < 10 ? score = string(10 - score.length(), ' ') + score : score = score.substr(0,10);
stu.school.length() < 20 ? stu.school = string(20 - stu.school.length(), ' ') + stu.school : stu.school = stu.school.substr(0,20);
stu.team.length() < 10 ? stu.team = string(10 - stu.team.length(), ' ') + stu.team : stu.team = stu.team.substr(0,10);
stu.status.length() < 10 ? stu.status = string(10 - stu.status.length(), ' ') + stu.status : stu.status = stu.status.substr(0,10);
//将学籍信息写入学籍数据文件末尾
sout<<id<<stu.name<<stu.dob<<stu.sex<<stu.gender<<stu.address<<score<<stu.school<<stu.team<<stu.status<<endl;
}
sout.close();
}
// 测试案例
int main() {
//LinkedBSTree<StudentIndex>* indexTree = new LinkedBSTree<StudentIndex>();// 搜索二叉树数据索引
//LinkedAVLTree<StudentIndex>* indexTree = new LinkedAVLTree<StudentIndex>();// AVL自平衡树数据索引
LinkedRBTree<StudentIndex>* indexTree = new LinkedRBTree<StudentIndex>();// 红黑树数据索引
lineNumber = 10000;//记录行数
//清空数据和索引文件
ofstream file1("student_db.txt", std::ios::trunc);
ofstream file2("student_index.txt", std::ios::trunc);
file1.close();
file2.close();
buildDate(lineNumber);// 生成学籍数据
buildIndex();// 生成索引数据
//loadIndex(indexTree);// 加载索引数据(普通版)
loadIndexNew(indexTree);// 加载索引数据(优化版)
findById(indexTree,5000);// 查询学生
Student stu = {10001,"eric101","2012-05-18","男","汉","湖南省湘潭县石潭镇",400,"石潭傎芙蓉中学","36","在读"};
inserStudent(indexTree, stu);//插入学生
findById(indexTree,10001);//查询学生
return 0;
}
输出结果
1005 aaaa5 2012-05-18 男 汉 湖南省湘潭县石潭镇400.000000 石潭傎芙蓉中学 36 在读
10001 aaaa9001 2012-05-18 男 汉 湖南省湘潭县石潭镇400.000000 石潭傎芙蓉中学 36 在读
总结
- 红黑树数据索引:查询效率高,插入、删除时因平衡机制带来了一定的开销,适合实时系统(随时可能进行数据插入、删除、查询操作),例如:
- 待支付订单数据
- 实时操作日志
- 搜索二叉树数据索引:插入、删除、查询效率不稳定,数据顺序决定操作效率。因为没有平衡机制,容易退化为线性结构(可以用实例一的方式生成平衡的搜索二叉树,后续不易进行插入和删除操作,否则破坏平衡),适合分析系统(只需查询操作)。
- 历史订单数据
- 历史操作日志
- 自平衡树数据索引:查询效率高,插入、删除时因严格平衡机制带来了不小开销,适合查多插少的系统(大量查询和少量插入、删除操作)。
- 已完成订单数据(少量需要退货)
- 产品数据(浏览量大,发布量小)
四、哈夫曼编码与解码
哈夫曼编码(Huffman Coding)是一种编码方式,在多个领域都有广泛的应用,包括但不限于文件压缩、网络传输、图像处理等。在文件压缩中,如ZIP和RAR格式,哈夫曼编码能显著减少存储空间的需求;在图像处理中,如JPEG图像格式,哈夫曼编码能有效提高压缩比,减少图像文件大小。
哈夫曼编码核心是构建最优前缀码二叉树(哈夫曼树),为高频字符分配短编码、低频字符分配长编码,实现平均码长最短,保证编码唯一可解码且无歧义。
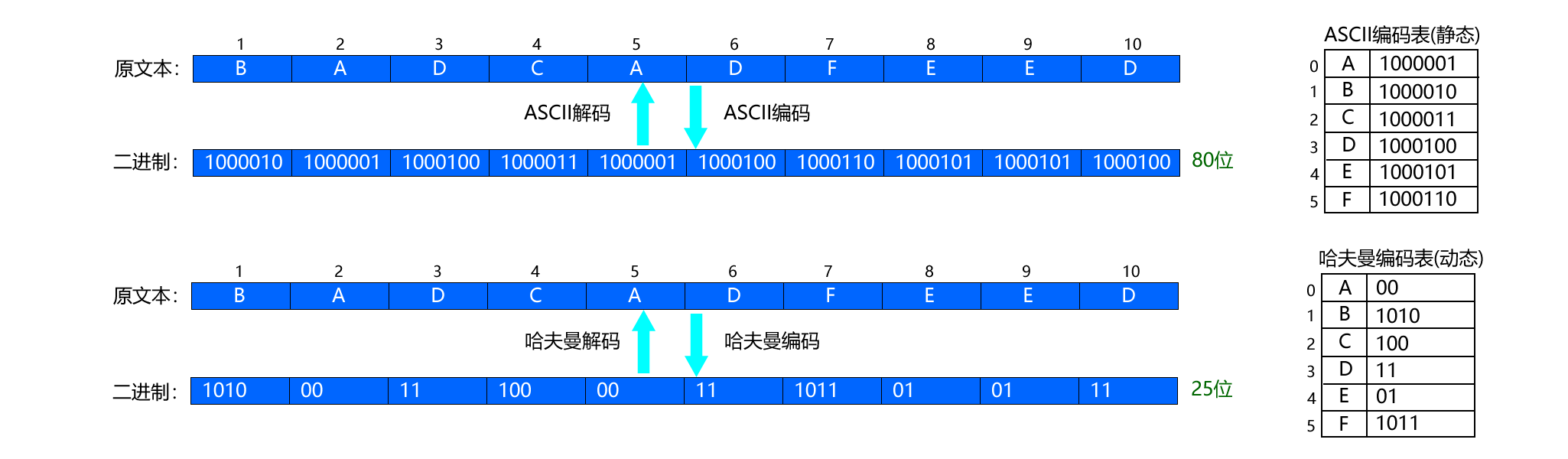
问题描述:
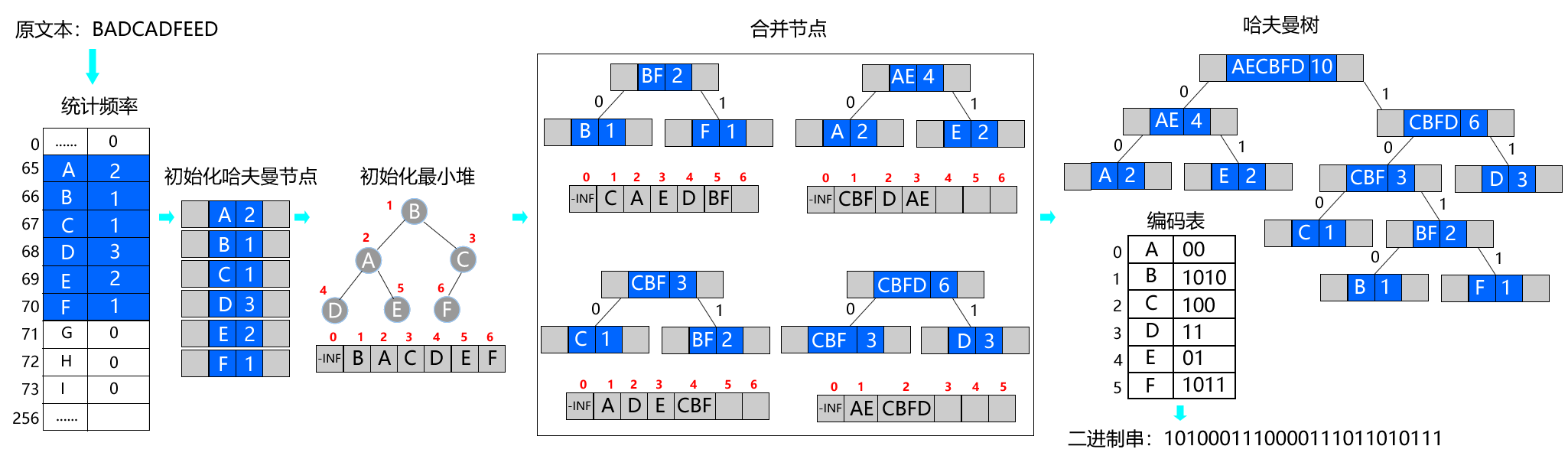
- 对“BADCADFEED”文本进行哈夫曼编码和解码操作。
- 哈夫曼编码表: 'A':00 'E':01 'C':100 'B':1010 'F':1011 'D':11
- 编码后的二进制串:1010001110000111011010111
- 解码后的文本:BADCADFEED
算法解析:
哈夫曼编码通过构建一棵特殊的二叉树——哈夫曼树来生成编码。树中的每个叶节点代表一个字符,而路径从根节点到叶节点则定义了该字符的编码,左分支代表0,右分支代表1。
- 构建哈夫曼树
这个过程可以通过优先队列(通常是最小堆)来高效实现,每次合并操作时弹出两个最小的元素,合并后将新树重新加入优先队列,继续操作直到只剩一个元素。
- 统计频率 :统计文本每个字符的出现次数。
- 初始化:根据统计后的字符频率数组,初始化哈夫曼树节点和哈夫曼小根堆。
- 合并操作 :将权值(频率)最小的两棵树或节点合并成一棵新树,新树的根节点权值为两个子树根节点权值之和。
- 重复操作 :重复合并操作,直到所有树合并为一棵树。
- 生成编码表
哈夫曼树中的每个叶节点代表一个字符,从根节点到叶节点的路径则代表该字符的编码。
- 编码
- 解码
哈夫曼解码是哈夫曼编码的逆过程,其核心是利用已构建的哈夫曼树(或等价的编码映射表),将二进制编码串还原为原始的字符序列。编码和解码必须使用同一套哈夫曼树,否则解码结果会完全错误。实际应用中,通常会将哈夫曼树的结构信息与编码串一起存储。
- 基于哈夫曼树的逐位遍历(推荐,节省空间)
解码流程
- 从哈夫曼树的根节点开始。
- 逐位读取二进制编码串:遇到 0,向左子树移动;遇到 1,向右子树移动。
- 当移动到叶子节点时,输出该叶子节点对应的字符。
- 回到根节点,重复上述步骤,直到二进制编码串全部处理完毕。
基于树的解码:无需存储反向编码表,节省空间,但需要逐位遍历树,时间复杂度为 O(n)(n 为编码串长度)。
- 基于反向编码表的匹配(简单直观,适合短编码)
前缀编码的重要性:正因为哈夫曼编码是前缀编码,解码时才不会出现 “一个编码是另一个编码前缀” 的歧义。例如:若 A 的编码是 0,则其他字符的编码不能以 0 开头。
基于映射表的解码:需要存储反向编码表,空间复杂度较高,但匹配速度快,适合编码长度较短的场景。
- 基于哈夫曼树的逐位遍历(推荐,节省空间)
逐个将原文本中的字符生成编码表中对应的编码,然后将每个字符的编码组合成一个二进制串。
#include <iostream>
#include "Entitys.h"
#include "ArrayHeap.h"
using namespace std;
// 统计字符频率(返回有效字符数)
int countFrequency(const char *text, int freq[MAX_CHAR]) {
memset(freq, 0, sizeof(int) * MAX_CHAR);
int len = strlen(text);
int uniqueCount = 0;
for (int i = 0; i < len; i++) {
unsigned char c = text[i]; // 避免负数
if (freq[c] == 0) uniqueCount++;
freq[c]++;
}
return uniqueCount;
}
// 构建哈夫曼树
HuffmanNode* buildHuffmanTree(const char *text) {
ArrayHeap<HuffmanNode*,HuffmanNodeCmp> heap;//最小堆
// 1. 统计字符频率
int freq[MAX_CHAR];
countFrequency(text, freq);
// 2. 初始化:根据统计后的字符频率数组,初始化哈夫曼树节点和哈夫曼小根堆。
for (int i = 0; i < MAX_CHAR; i++) {
if (freq[i] > 0) {
HuffmanNode* node = new HuffmanNode({i,freq[i]});
heap.put(node);
//heap.print();
}
}
// 3. 合并节点,构建哈夫曼树
while (heap.size() > 1) {
// 取出频率最小的两个节点
HuffmanNode* left = heap.get();
HuffmanNode* right = heap.get();
// 最小的两棵树或节点合并成一棵新树(字符为'\0',频率为两者之和)
HuffmanNode* parent = new HuffmanNode({'\0', left->freq + right->freq});
parent->left = left;
parent->right = right;
// 新树入堆
heap.put(parent);
}
// 堆中最后一个节点就是根节点
return heap.get();
}
// 释放哈夫曼树内存
void freeHuffmanTree(HuffmanNode *root) {
if (root == NULL) return;
freeHuffmanTree(root->left);
freeHuffmanTree(root->right);
free(root);
}
// 递归生成哈夫曼编码(辅助函数)
void generateCodeHelper(HuffmanNode *node, char *code, int codeLen, CodeTable *codeTable, int *tableIdx) {
if (node == NULL) return;
// 叶子节点:保存编码
if (node->left == NULL && node->right == NULL) {
codeTable[*tableIdx].ch = node->ch;
code[codeLen] = '\0';
strcpy(codeTable[*tableIdx].code, code);
(*tableIdx)++;
return;
}
// 记录从根节点到叶子节点路径,左子树存储0,右子树存储1
code[codeLen] = '0';
generateCodeHelper(node->left, code, codeLen + 1, codeTable, tableIdx);
code[codeLen] = '1';
generateCodeHelper(node->right, code, codeLen + 1, codeTable, tableIdx);
}
// 生成哈夫曼编码表(返回编码表长度)
int generateHuffmanCode(HuffmanNode *root, CodeTable *codeTable) {
char code[MAX_CODE_LEN];
int tableIdx = 0;
generateCodeHelper(root, code, 0, codeTable, &tableIdx);
return tableIdx;
}
// 哈夫曼编码:返回编码后的字符串(需手动free)
char* huffmanEncode(const char *text, CodeTable *codeTable, int tableLen) {
int len = strlen(text);
// 预估编码长度(足够大)
char *encoded = (char*)malloc(len * MAX_CODE_LEN + 1);
encoded[0] = '\0';
for (int i = 0; i < len; i++) {
char c = text[i];
// 查找当前字符的编码
for (int j = 0; j < tableLen; j++) {
if (codeTable[j].ch == c) {
strcat(encoded, codeTable[j].code);
break;
}
}
}
return encoded;
}
// 哈夫曼解码:返回解码后的字符串(需手动free)
char* huffmanDecode(const char *encoded, HuffmanNode *root) {
int len = strlen(encoded);
char *decoded = (char*)malloc(len + 1); // 解码后长度不超过编码长度
int decodeIdx = 0;
HuffmanNode *current = root;
for (int i = 0; i < len; i++) {
// 按二进制位遍历,左0右1
if (encoded[i] == '0') {
current = current->left;
} else if (encoded[i] == '1') {
current = current->right;
}
// 到达叶子节点,记录字符
if (current->left == NULL && current->right == NULL) {
decoded[decodeIdx++] = current->ch;
current = root; // 回到根节点,继续解码下一个字符
}
}
decoded[decodeIdx] = '\0';
return decoded;
}
// 测试案例
int main() {
// 1. 构建哈夫曼树
char text[]={"1111111111111111112222222222222222223333333333333333334444444"};
HuffmanNode *root = buildHuffmanTree(text);
// 2. 生成编码表
CodeTable codeTable[MAX_CHAR]; // 足够存储所有ASCII字符
int tableLen = generateHuffmanCode(root, codeTable);
// 打印编码表
printf("哈夫曼编码表:\n");
for (int i = 0; i < tableLen; i++) {
printf("'%c' : %s\n", codeTable[i].ch, codeTable[i].code);
}
// 3. 编码
char *encoded = huffmanEncode(text, codeTable, tableLen);
printf("\n编码后的二进制串:%s\n", encoded);
// 4. 解码
char *decoded = huffmanDecode(encoded, root);
printf("\n解码后的文本:%s\n", decoded);
// 释放内存
free(encoded);
free(decoded);
freeHuffmanTree(root);
return 0;
}
输出结果
哈夫曼编码表:
'A' : 00
'E' : 01
'C' : 100
'B' : 1010
'F' : 1011
'D' : 11
编码后的二进制串:1010001110000111011010111
解码后的文本:BADCADFEED
五、Top K 问题
Top K 问题是从海量数据中找出前 K 个最大 / 最小的元素。常见应用场景包括:热搜榜单、Top K 高频词、成绩排名等。
问题描述:
- 给定一个无序数组 nums 和整数 K,要求找出其中 前 K 大 的元素(同理可推导前 K 小的元素)。
- 约束 1:数据量可能极大(如 1000 万条),直接排序效率低。
- 约束 2:K 通常远小于数据总量(如 K=10,数据量 = 10^6)。
算法解析:
维护一个大小为 K 的 小根堆,遍历数组时
- 若堆中元素不足 K 个,直接入堆。
- 若堆已满,且当前元素大于堆顶元素,弹出堆顶,将当前元素入堆。
- 最终堆中元素即为前 K 大的元素。
#include <iostream>
#include"ArrayQueue.h"
using namespace std;
//Top K查找
vector<int> topK_Heap(vector<int>& nums, int k)
{
ArrayHeap<int> heap;//最小堆
for(int i=0; i < nums.size(); i++)
{
if(heap.size() < k)
{
heap.put(nums[i]); //若堆中元素不足 K 个,直接入堆。
}
else
{
//当前元素大于堆顶元素,弹出堆顶,将当前元素入堆。
if(nums[i] > heap.getMin())
{
heap.get();
heap.put(nums[i]);
}
}
}
// 提取堆中元素
vector<int> res;
while (!heap.isEmpty()) {
res.push_back(heap.get());
}
return res;
}
// 测试案例
int main() {
vector<int> nums = {90, 89, 86, 100, 95, 97, 87, 92, 60, 76, 77};
int k = 3;
vector<int> res = topK_Heap(nums, k);
cout << "成绩前" << k << ":";
for(int i=res.size()-1;i>=0;i--)
{
cout << res[i] << " ";
}
return 0;
}
输出结果
成绩前3名:100 97 95
六、单词搜索
问题描述:
- 给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。
- 单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
- 提示:
- m == board.length
- n == board[i].length
- 1 <= m, n <= 12
- board[i][j] 是一个小写英文字母
- 1 <= words.length <= 3 * 104
- 1 <= words[i].length <= 10
- words[i] 由小写英文字母组成
- words 中的所有字符串互不相同
- 示例 1:
- 输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"]
- 输出:["eat","oath"]
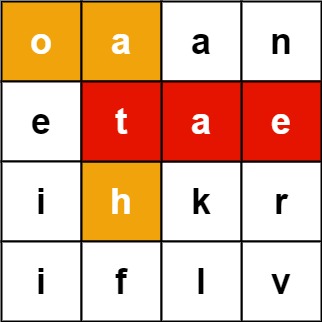
算法解析:
直接对每个单词做 DFS 会超时,最优解法是:
- 构建前缀树(Trie):把所有目标单词存入前缀树,利用前缀树的特性剪枝无效搜索;
- 网格 DFS 遍历:从网格每个位置出发,结合前缀树深度优先搜索,匹配到完整单词时加入结果集。
- 边界剪枝:越界、已访问、字符不在前缀树中时直接返回;
- 标记访问:避免同一单元格重复使用;
- 方向遍历:递归搜索上下左右四个方向;
- 回溯:递归结束后取消访问标记,让该单元格能被其他路径使用。
#include <iostream>
#include <vector>
#include <unordered_set>
#include"Trie.h"
using namespace std;
// 四个方向:上下左右
vector<pair<int, int>> dirs = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
// DFS 搜索函数
void findWords(vector<vector<char>>& board, int x, int y, TrieNode* node, string& path, Trie& trie, unordered_set<string<& result) {
int rows = board.size();
int cols = board[0].size();
// 边界条件剪枝:越界、当前字符不匹配、已访问(标记为'#')
if (x < 0 || x >= rows || y < 0 || y >= cols || board[x][y] == '#' ||
node->children[board[x][y] - 'a'] == nullptr) {
return;
}
// 1. 记录当前字符,更新路径和Trie节点
char currChar = board[x][y];
path.push_back(currChar);
node = node->children[currChar - 'a'];
// 2. 找到完整单词:加入结果集 + 从Trie中删除(避免重复匹配)
if (node->is_end) {
result.insert(path);
trie.remove(path);
}
// 3. 标记当前位置为已访问(修改board节省空间)
board[x][y] = '#';
// 4. 遍历四个方向递归搜索
for (auto& dir : dirs) {
int nx = x + dir.first;
int ny = y + dir.second;
findWords(board, nx, ny, node, path, trie, result);
}
// 5. 回溯:恢复字符 + 回退路径
board[x][y] = currChar;
path.pop_back();
}
// 测试案例
int main() {
Trie trie; // 定义Trie树
vector<vector<char>> board={
{'o','a','a','n'},
{'e','t','a','e'},
{'i','h','k','r'},
{'i','f','l','v'}
};// 定义二维字符网格
vector<string> words={"oath","pea","eat","rain"};// 定义单词列表
string path; // 记录当前DFS路径
// 1. 构建前缀树
for(string item : words)
{
trie.insert(item);
}
// 2. 遍历网格,执行DFS
unordered_set<string> result_set; // 去重
int rows = board.size();
if (rows == 0) return;
int cols = board[0].size();
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < cols; ++j) {
findWords(board, i, j, trie.root, path, trie, result_set);
}
}
// 3. 输出结果
for (string s : result_set) {
cout << s << " ";
}
return 0;
}
输出结果
eat oath
七、总结
树结构作为非线性层次化数据结构,凭借其独特的层级特性和高效的操作效率,成为处理海量数据、有序存储、快速检索类问题的核心解决方案。本文围绕树结构的经典应用场景展开讲解,核心要点总结如下:
- 不同树结构的场景适配性:
- 二叉搜索树(BST):适合静态、只读的分析类场景(如历史日志查询),但有序数据易退化为线性结构,需通过平衡化优化;
- 平衡二叉树(AVL / 红黑树):AVL 严格平衡,查询效率极高,适合查多插少的场景(如产品数据索引);红黑树平衡开销更低,兼顾插入 / 删除 / 查询效率,是实时系统(如 Redis 有序集合、学籍索引)的首选;
- 堆(完全二叉树):依托 “快速访问最值” 的特性,是 Top K 问题、优先队列的最优解,空间复杂度仅 O (K),适配海量 / 流式数据场景;
- 哈夫曼树:通过字符频率构建最优前缀码树,实现数据高效压缩,是文件压缩、网络传输的核心算法。
- 核心应用场景的实现逻辑:
- 数据存储:利用有序数组构建平衡 BST,通过 “选中间节点为根” 避免树退化,保证增删查改的均衡效率;
- 数据索引:基于红黑树 / AVL/BST 构建索引模块,将 “文件行号 - 数据主键” 映射存储,把海量数据的磁盘查询转化为树的 O (logn) 内存查询,大幅提升检索性能;
- 哈夫曼编码 / 解码:通过最小堆构建哈夫曼树,为高频字符分配短编码,实现数据压缩;解码时依托哈夫曼树的路径特性,逐位还原原始字符,保证无歧义解码;
- Top K 问题:维护大小为 K 的小根堆,遍历数据时仅保留前 K 大元素,在 O (n logK) 时间复杂度内解决海量数据的 Top K 筛选,兼顾效率与内存占用。
树结构的应用本质是 “用空间换时间”,通过合理的层级组织和平衡机制,将线性操作的 O (n) 复杂度优化为对数级,是解决大数据时代性能瓶颈的关键工具。掌握不同树结构的特性与场景适配,能大幅提升数据处理类项目的设计与实现能力。
返回顶部